

The Problem That Makes or Breaks AI Agents
Picture an AI assistant that helps a software team manage their projects. On Monday it helps a developer debug a tricky function. On Tuesday the same developer comes back with a follow-up question. The agent has no idea who this person is. It has forgotten the entire conversation. Every session starts completely fresh. That is the stateful challenge, and it is one of the most significant limitations in real-world AI agent deployment right now. A system that forgets everything after each session cannot build relationships, cannot improve from experience, and cannot handle tasks that span more than a single conversation. According to research published by the AI lab Letta in 2024, over 70 percent of enterprise AI agent deployments report that the lack of persistent memory is the primary bottleneck preventing agents from handling complex, multi-session workflows. The models themselves are capable enough. The missing piece is memory. This article explains what memory architecture actually means for AI agents, why solving the stateful problem matters so much, and what the practical approaches look like for teams building agents in 2026.
Section 1: Why AI Agents Forget and Why That Is a Real Problem
Understanding the memory problem starts with understanding how large language models work at a basic level. When an agent processes a conversation, it works within something called a context window. Think of the context window as the agent's short-term working memory. Everything it knows about the current conversation lives inside that window. Once the conversation ends, that window is cleared. The next session starts with a blank slate. There is no carry-over, no memory of who the user is, no recall of decisions made last week, and no awareness of progress on ongoing tasks. The agent is, in a very real sense, born again at the start of every session. This is not just a minor inconvenience. It is a fundamental barrier to useful agentic behavior. Genuine intelligence, whether human or artificial, depends on the ability to learn from experience and apply that learning to new situations. An agent that cannot do this is not truly learning. It is just responding. The context window limitation also creates a practical ceiling. As tasks grow more complex and conversations span more turns, the context window fills up. Older information gets pushed out to make room for newer input. The agent starts losing track of earlier parts of the conversation even within a single session. This is a problem that memory architecture is specifically designed to solve.
Section 2: The Four Memory Types Every Agent Architecture Needs
When engineers talk about memory architecture for AI agents, they are not talking about one single system. They are talking about a layered approach that mirrors, in a rough way, how human memory works. There are four distinct types that a well-designed agent system needs to support.
Key Takeaways: The Four Memory Types at a Glance
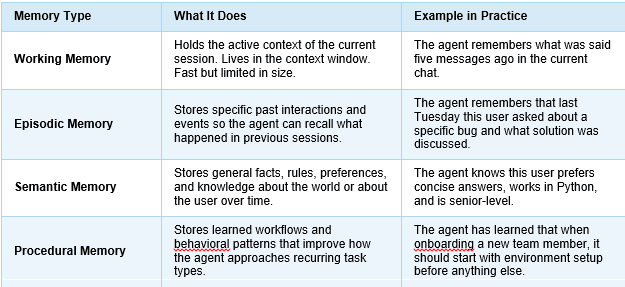
Not all agents need all four types equally. A customer support agent might rely heavily on episodic and semantic memory. A coding assistant might lean more on procedural memory. The design decision about which memory types to prioritize should come directly from the use case, not from what is easiest to implement.
Section 3: How Memory Is Actually Built in Practice
The theory of memory types is clear enough. The harder question is how to actually build these systems. In 2026, there are several established patterns that engineering teams are using, each with its own tradeoffs. Vector Databases as Long-Term Memory Stores Vector databases like Pinecone, Weaviate, and Chroma have become the standard infrastructure for agent long-term memory. The way they work is fairly straightforward: past interactions, user preferences, and factual knowledge are converted into numerical representations called embeddings and stored in the database. When the agent needs to retrieve relevant memory, it converts the current context into an embedding and runs a similarity search. The database returns the stored memories that are most semantically related to what the agent is currently dealing with. This approach scales well and is fast enough for real-time use. The challenge is retrieval quality. Not every relevant memory will surface on every search, and irrelevant memories can sometimes appear. Teams working on production memory systems spend significant time tuning the retrieval layer to improve precision. Structured Memory Stores for User Profiles and Preferences For semantic memory specifically, many teams use structured storage alongside or instead of vector databases. A simple key-value store or relational database can hold facts about a user: their name, their role, their stated preferences, their active projects. This data is updated over time as the agent learns more. The advantage here is precision. When the agent needs to know the user's preferred programming language, it does not need to run a similarity search. It looks up a specific field. Combining structured stores for known facts with vector search for contextual recall gives agents a much more reliable memory system than either approach alone. Memory Summarization to Manage Storage Costs One practical challenge that every team running persistent agent memory faces is storage growth. An agent that interacts with thousands of users across months of sessions will accumulate enormous amounts of raw interaction data. Storing all of it is expensive. Retrieving from it gets slower as it grows. The solution most teams use is periodic summarization. Rather than storing every individual message, the system periodically compresses older interactions into concise summaries. A week of daily conversations becomes a short paragraph capturing the key facts and decisions from that period. This approach was described in detail in the MemGPT paper published by researchers at UC Berkeley in 2023, which is widely cited as a foundational framework for agent memory management.
Section 4: The Stateful Design Checklist for Agent Memory Systems
For teams designing or evaluating agent memory systems, here is a practical checklist drawn from real production deployments. These are the decisions that determine whether an agent memory system works at scale or breaks under pressure.
- Define which memory types the use case actually requires. Do not build all four by default. A customer-facing agent and an internal workflow agent have very different memory needs. Start with what the agent genuinely needs to remember to be useful.
- Choose the right storage layer for each memory type. Use vector databases for episodic and contextual retrieval. Use structured stores for facts and preferences. Do not try to use a single storage system to handle everything.
- Build memory write logic as carefully as memory read logic. Deciding what gets stored is just as important as deciding what gets retrieved. Noisy or low-quality memory storage leads to noisy and unreliable retrieval. Set clear criteria for what qualifies as worth remembering.
- Implement a summarization pipeline from day one. Do not wait until storage costs become a problem. Design the compression and summarization process before the data starts accumulating.
- Give users visibility and control over their stored memory. This is both a trust issue and increasingly a regulatory one. Users should be able to see what the agent remembers about them, correct errors, and delete specific memories. Systems that do not offer this will face problems as data privacy expectations tighten in 2026 and beyond.
- Test memory retrieval under realistic load. A retrieval system that works well in development with a few hundred stored items can degrade significantly in production with millions. Load testing the memory layer is a step many teams skip and then regret.
- Monitor memory staleness. Facts change. A user's role, their preferences, their active projects, all of these evolve over time. Build processes to flag and refresh outdated memory so the agent is not acting on information that is no longer accurate.
The Final Answer: Memory Is the Difference Between a Tool and an Agent
Here is the honest summary of where things stand. AI models in 2026 are genuinely impressive at reasoning within a single conversation. But a single conversation does not make an agent. An agent is something that operates over time, builds on past experience, and becomes more useful the longer it works with you. Memory architecture is the foundation that makes that possible. Without it, even the most capable model is just a very smart tool that resets every time you use it. With a well-designed memory system, that same model becomes an agent that learns your preferences, remembers your context, handles multi-session tasks without losing the thread, and gets genuinely better over time. The four memory types, working, episodic, semantic, and procedural, each solve a different part of the stateful challenge. The storage patterns, vector databases for contextual recall, structured stores for facts, summarization pipelines for cost management, give teams practical tools to implement those memory types at scale. The teams that get this right will build agents that users actually keep coming back to. Not because the underlying model is special. But because the agent knows them, remembers them, and gets more useful with every interaction. That is what persistent learning looks like in practice. And right now, memory architecture is the most direct path to achieving it.
Your Next Step
Before picking a vector database or designing a retrieval pipeline, go back to the use case and answer one question clearly: what does this agent need to remember in order to be genuinely useful in session three, session ten, and session fifty? The answer to that question will define the memory architecture far more precisely than any framework or tool comparison ever could.
